Le leader produit Olivier Courtois dévoile comment il utilise les serveurs MCP de Linear, Notion ou encore Figma pour accélérer son process produit. Nous reproduisons ici l’article de sa série AI Bites, dédiée à l’IA pour les équipes produit, publiée dans sa newsletter productver.se.
⌛ 3 min de lecture pour multiplier les tickets 🎟️
🔗 Un article issu de l’édition #3 de la newsletter AI Bites (en 🇬🇧)
| 📌 Dans cet article, tu vas apprendre : > Ce qu’est un serveur MCP et comment les utiliser > Comment gérer son backlog avec les MCP > Comment communiquer son avancement avec les MCP |
Avant de plonger dans le vif du sujet, sachez que Claire Vo a publié une vidéo avec Dennis Yang (Chime) où il présente son workflow Cursor (99% similaire à celui que je vais décrire ci-dessous). À regarder si vous préférez une version vidéo (plus longue).
💡 Qu’est-ce qu’un serveur MCP ?
J’utilise plusieurs serveurs MCP dans mon quotidien. Voici donc une définition rapide :
Le Model Context Protocol (MCP) est un standard pour connecter des applications IA à des systèmes externes. En gros, c’est une API conçue pour les LLM. Ce qui signifie qu’elle peut facilement découvrir les capacités disponibles, les utiliser, répondre aux questions, et effectuer des actions.
2 types de serveurs existent :
- les serveurs publics (généralement il y a une URL publique que vous référencez) utilisables en version web et desktop
- les serveurs locaux (qui peuvent utiliser des commandes ou des programmes, sur votre ordinateur) utilisables uniquement depuis une application IA desktop
La plupart des outils pour les Product Managers comme Notion, Linear, Figma ou Amplitude, se sont précipités pour sortir leur « serveur MCP » public utilisables dans les applications IA comme Claude, Cursor ou même des agents comme Claude Code / Codex.
Si tu veux plus d’infos sur les MCP, découvre l’article dédié du Ticket :

✨ Quelle IA devriez-vous utiliser comme copilote ? (et pourquoi j’utilise Cursor)
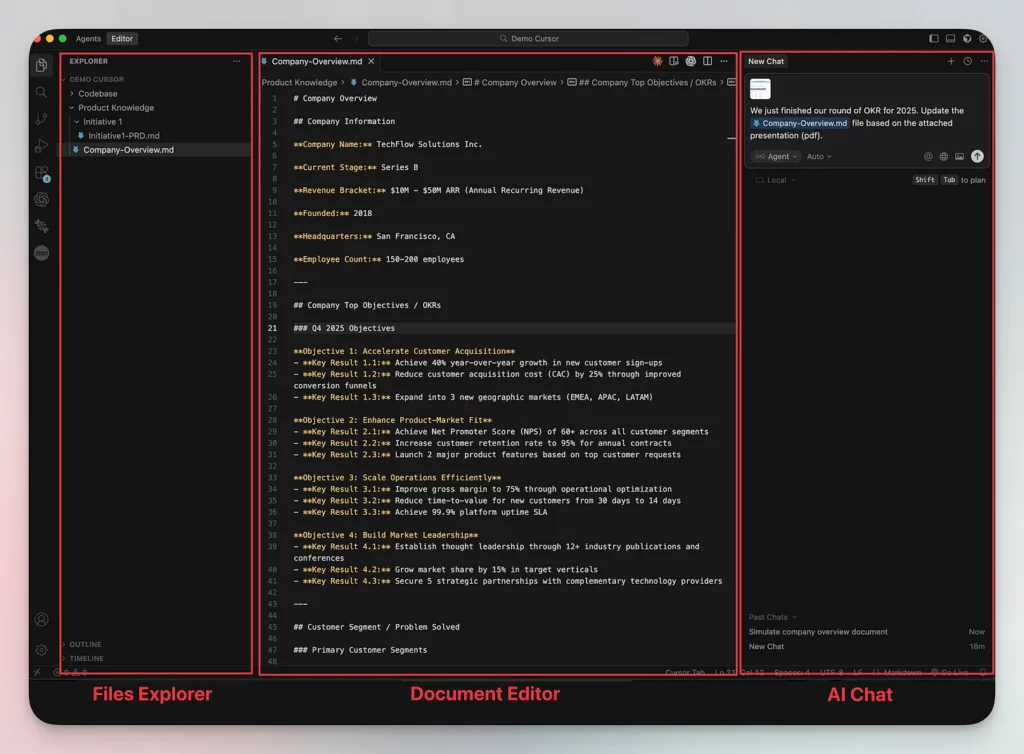
J’utilise personnellement Cursor depuis 2 ans (pour développer), mais c’est désormais ma façon préférée d’éditer des fichiers et de créer des projets (tâches non-développeur). Maintenant je peux :
- Créer un simple dossier sur mon ordinateur avec quelques fichiers de connaissances qui sont complètement « portables »
- Ajouter quelques règles Cursor (= raccourcis) pour automatiser mes prompts habituels comme écrire des tickets, cadrer mon périmètre ou écrire un rapport d’avancement.
- Brancher des serveurs MCP pour être efficace (Linear/Notion pour l’accès au backlog, Granola pour l’accès aux transcriptions de réunions, Figma pour l’accès au design, Amplitude pour l’accès aux données…).
- Discuter « avec le dossier » pour brainstormer, analyser des données, travailler sur des PRD, et plus encore.
- Créer des fichiers avec l’IA, mais surtout reprendre la main dessus, et les éditer manuellement dans l’éditeur.
Si Cursor vous intéresse mais que vous ne savez pas par où commencer, je vous recommande cet article : « The Modern AI workspace« .
Évidemment, ça ne va pas être la tasse de thé de tout le monde, donc voici une comparaison des principaux outils que vous pouvez utiliser pour exploiter la puissance des MCPs, et mon cas d’usage pour chacun 👇
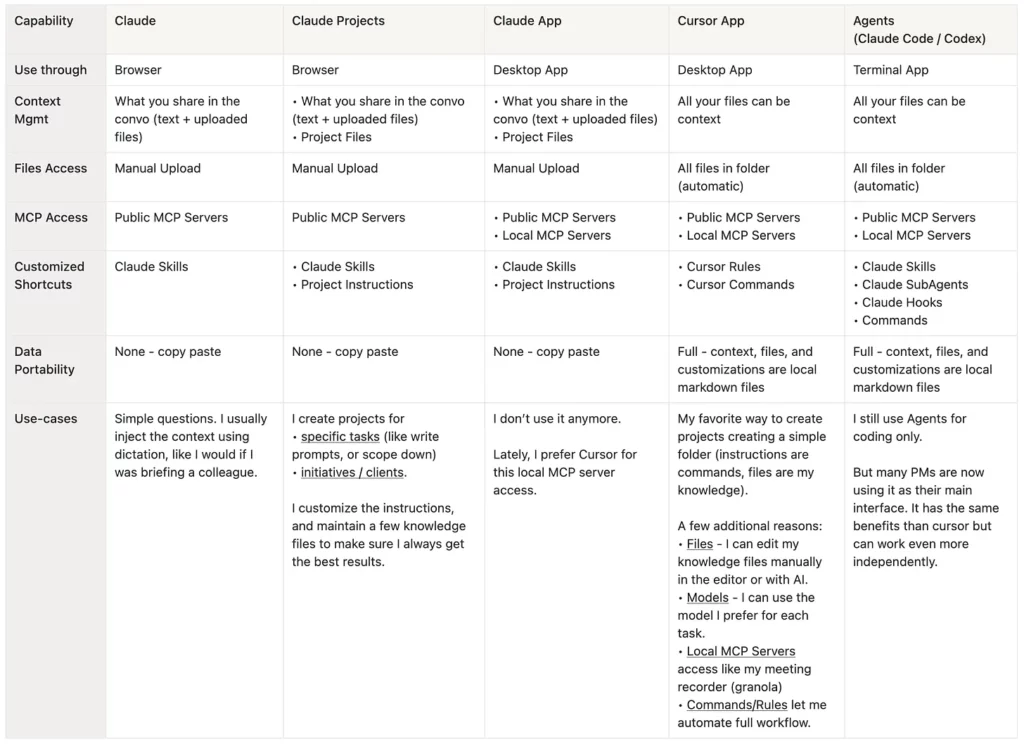
Note : Ce tableau est inspiré de cet article de Teresa Torres sur Claude Code. Une lecture hautement recommandée !
🛫 Cas d’usage n°1 : Backlog Autopilot
Je collabore avec des équipes qui hébergent leurs tickets dans Notion ainsi que dans Linear. Heureusement, les deux ont des serveurs MCP que je peux utiliser pour piloter mon backlog.
Note : Ci-dessous je vais partager des exemples de prompts écrits pour Linear (mais ça fonctionne de la même façon pour les autres MCP).
Le plus souvent, je crée des tickets directement dans le backlog avec quelques bullet points (= des notes pour moi-même). Puis, quand j’ai besoin de vraiment écrire le contenu, je vais demander à l’IA de lire le ticket, collaborer avec moi, puis le mettre à jour dans le backlog.
Comment je complète un ticket spécifique
Pour écrire ce prompt j’ai utilisé la méthode suivante :
- J’ai commencé un nouveau chat en expliquant mon objectif : « crée une nouvelle commande qui va lire le contenu d’un ticket via le MCP Linear, m’interviewer, puis me suggérer une ré-écriture du ticket. Une fois que je l’aurais approuvé, mets à jour le ticket dans le backlog Linear »
- Cursor m’a proposé le prompt ci-dessous. Dans le chat, j’ai précisé mes « directives de rédaction », dans mon cas, j’ai juste collé les instructions que j’ai partagées dans l’article précédent.
- J’ai itéré sur le niveau de détails, et les règles pour m’assurer que ça fonctionne 99% du temps.
Pour utiliser ce prompt, voici comment je m’y prends :
1- J’ouvre Cursor, et j’entre la commande : « /ticket-refine » avec l’url du ticket.
2- A partir de là Cursor lit le ticket, me pose des questions, on échange et quand je suis satisfait je lui demande de mettre à jour le backlog. J’obtiens ainsi systématiquement des tickets de meilleures qualités avec des edges cases spécifiés, une recherche poussée ainsi que les critères d’acceptances (que je n’écrivais jamais auparavant).
3- Quand des informations supplémentaires peuvent être utiles pour améliorer les échanges et la rédaction du ticket :
- J’utilise les mentions Cursor, pour attacher des fichiers de connaissances spécifiques présents dans le dossier. J’ajoute « @nomdefichier », et le prompt de refinement de ticket va lire mon PRD ou des extraits de recherche utilisateur cités.
- Je demande à l’IA d’utiliser des serveurs MCP supplémentaires comme Amplitude / Posthog pour extraire des données, Figma pour analyser le design, etc.
# ticket-refine
## Workflow
### 1. Fetch Ticket from Linear
**Input**: User provides either a Linear ticket URL (e.g., `https://linear.app/acme-corp/issue/PROJ-456`) or ticket ID (e.g., `PROJ-456` or UUID).
**Actions**:
- Extract ticket ID from URL if provided, otherwise use ID directly
- Use `mcp_Linear_get_issue(id: ticket_id)` to fetch full ticket details
- Extract: `title`, `description`, `state`, `assignee`, `labels`, `priority`, `project`, `team`
- Parse description for: Design links, Problem statement, Solution description, Analytics context, and any existing acceptance criteria/edge cases
### 2. Interview Phase - Ask Clarifying Questions
Act as an **experienced Product Manager interviewer** to gather missing information needed for the INVEST story format.
**Questions Strategy**:
- Start with **blocking questions** (if critical unknowns detected)
- Then ask **clarifying questions** for missing fields
- Focus on extracting the four core fields: Design links, Problem, Solution, Analytics baseline
[too long...] Tap the button to access the whole prompt=> Accéder au prompt complet
📣 Cas d’usage n°2 : Communiquer ses avancées
Nous passons énormément de temps à communiquer sur nos progrès, nos challenges et nos plans. Puis nous reformulons le même message pour différentes audiences. Heureusement pour nous, l’IA est assez efficace pour écrire et reformuler.
Pour des raisons pédagogiques, je partage 2 versions de ce prompt afin de montrer mon processus de réflexion.
Version 1 : rapport simple (backlog)
- J’ai commencé par revoir quelques exemples de communications que j’avais écrites. Généralement, elles contiennent des sections comme : Exec Sum, In Progress, Recently Done, Needs Attention.
- J’ai connecté Cursor avec le Linear MCP (pour accéder aux infos du backlog)
- J’ai créé une commande Cursor (= un raccourci) appelée /progress-report qui accède à Linear, lit les tickets, puis écrit un rapport de progrès.
- Pour l’utiliser je tape /progress-report, quelques minutes plus tard j’obtiens un rapport super précis, que je n’ai plus qu’à partager sur slack ou par email.
Le prompt anonymisé 👇
Please check what’s in our current backlog in Linear MCP and let me know what is in progress, what has been done recently (last 7d), and if there was any progress. If some issues needs design, give me an overview. If comments are unanswered in some issues, let me know.
Make sure to not talk about cancelled or deleted issues.
Format the report like this:
```markdown
## Summary
- **Progress**:
- **Design bottleneck**:
- **Pending (comments, decisions, blockers)**:
- **Recommended next steps**:
## 📊 In Progress (4 issues)
- ID - Issue Name 1 (Assignee)
- Description of the issue
- Highlights (if any)
- Remaining work (if any)
[too long...] Tap on the button to access the prompt=> Accéder au prompt complet
Version 2 : rapport avancé (backlog et réunions)
Je me suis rendu compte qu’une grande partie des informations clés se trouvent en dehors des tickets Linear. Mais j’ai de la chance : mes collègues acceptent que j’utilise un enregistreur de réunions, et comme je travaille à distance, presque 100 % de mes réunions sont donc enregistrées.
1- J’ai connecté Granola MCP pour accéder à mes transcriptions de réunions (Granola est l’outil que j’utilise.
2- J’ai amélioré les instructions du rapport d’avancement précédent afin de suivre ce processus précis :
- → Rassembler le contexte (depuis Linear et Granola)
- → Rechercher les données
- → Extraire les faits
- → Filtrer
- → Rédiger le rapport.
3- J’ai utilisé ce prompt pendant quelques jours et je me suis rendu compte que les appels MCP pouvaient être plus rapides s’ils étaient décrits en détail. J’ai donc demandé à mon assistant IA d’ajouter les noms des fonctions à utiliser.
4- Pour l’utiliser je tape /progress-report et j’obtiens un rapport précis tenant compte du contenu des tickets et des discussions qu’on a eu.
Voici mon prompt exhaustif et anonymisé 👇
## Workflow
### 1. Gather Time Context
- Default time window: **last 7 days** (one sprint = 1 week)
- If user specifies different window, use that
- Apply recency bias: weight most recent items highest
### 2. Scan Data Sources
#### Linear MCP
**Team**: “Your Team Name” (single team, do not use cycles)
**Step 1: Get Team & Verify States**
- Get team details: `mcp_Linear_get_team(query: “Your Team Name”)` to get team ID
- Optional: Get available states: `mcp_Linear_list_issue_statuses(team: “Your Team Name”)` to verify exact state names
**Step 2: List Issues for Team**
- List all issues for “Your Team Name” team: `mcp_Linear_list_issues(team: “Your Team Name”, includeArchived: false)`
- **Important**: After getting issues, filter out:
- Issues with state “Cancelled” or “Canceled” (check `state.name`)
- Issues with label “Duplicate” (check `labels` array for “Duplicate” label)
- Issues with title containing “duplicate” (case-insensitive)
- Archived issues (already filtered by `includeArchived: false`, but double-check)
[too long...] Tap on the button to access the whole prompt=> Accéder au prompt complet
À propos de Olivier Courtois

Olivier travaille dans le produit et le design depuis une quinzaine d’années. Il a notamment été Lead Product Manager de ManoMano ou VP Product de Comet. Aujourd’hui à son compte, il est l’auteur des newsletters Productverse et AI Bites.
| Pour s’abonner à la newsletter AI Bites, c’est par ici ✨ |

Sur le même thème

Les avantages du Ticket Premium : Le Ticket x AI Discipline
Tu veux apprendre à mettre de l’IA dans ta vie de product de manière (très) concrète ? Les formations AI Discipline sont à prix réduits avec Le…

J’ai cherché un job de Product Manager à New York : voici mon retour d’expérience.
Tribune de Lery Jiquel, Product Manager et auteur de la newsletter le Concentré Vélo, sur son expérience de recherche de job à New-York.

Product-Market Fit : Le framework incontournable de First Round Capital pour réussir à percer sur un marché
Découvre la synthèse du framework en 4 niveaux sur le Product-Market Fit du fonds d’investissement First Round, pour percer sur un marché.

Pourquoi Fleet, valorisé 100 M€, mène une opération de LBO
Interview de Sevan Marian, CEO et cofondateur de Fleet, sur les raisons du LBO de la startup de leasing informatique auprès d’ISAI Expansion.

Comment Le Monde réinvente sa stratégie produit pour faire face aux géants de l’IA générative
Reportage chez Le Monde qui multiplie les initiatives à l'ère de l'IA, afin de réduire sa dépendance à Google, OpenAI ou Perplexity.

5 leçons concrètes pour que ses OKR fonctionnent (enfin)
Synthèse des 5 apprentissages clés d'une session de coaching de la Head of Product Yolaine Mercier(ex France TV et Ubisoft) sur les OKR.